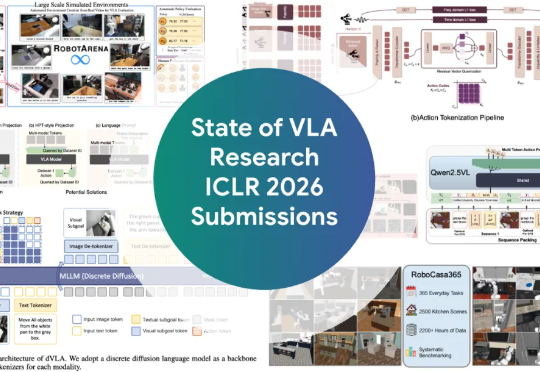
最火VLA,看这一篇综述就够了
最火VLA,看这一篇综述就够了ICLR 2026爆火领域VLA(Vision-Language-Action,视觉-语言-动作)全面综述来了! 如果你还不了解VLA是什么,以及这个让机器人学者集体兴奋的领域进展如何,看这一篇就够了。
来自主题: AI技术研报
9639 点击 2025-10-31 14:59
 搜索
搜索
ICLR 2026爆火领域VLA(Vision-Language-Action,视觉-语言-动作)全面综述来了! 如果你还不了解VLA是什么,以及这个让机器人学者集体兴奋的领域进展如何,看这一篇就够了。

2023年Meta推出SAM,随后SAM 2扩展到视频分割,性能再度突破。近日,SAM 3悄悄现身ICLR 2026盲审论文,带来全新范式——「基于概念的分割」(Segment Anything with Concepts),这预示着视觉AI正从「看见」迈向真正的「理解」。
说出概念,SAM 3 就明白你在说什么,并在所有出现的位置精确描绘出边界。 Meta 的「分割一切」再上新? 9 月 12 日,一篇匿名论文「SAM 3: SEGMENT ANYTHING WITH CONCEPTS」登陆 ICLR 2026,引发网友广泛关注。
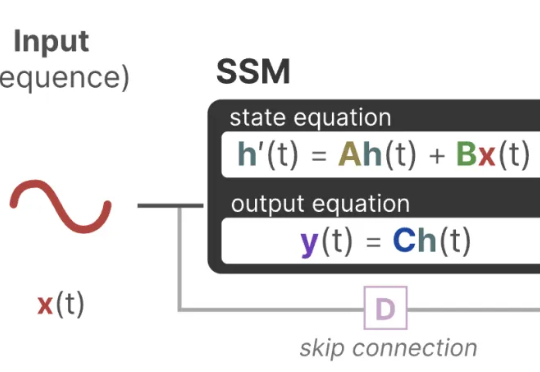
曼巴回来了!Transformer框架最有力挑战者之一Mamba的最新进化版本Mamba-3来了,已进入ICLR 2026盲审环节,超长文本处理和低延时是其相对Transformer的显著优势。另一个挑战者是FBAM,从不同的角度探索Transformer的下一代框架。

刚刚,又一个人工智能国际顶会为大模型「上了枷锁」。 ICLR 2025 已于今年 4 月落下了帷幕,最终接收了 11565 份投稿,录用率为 32.08%。
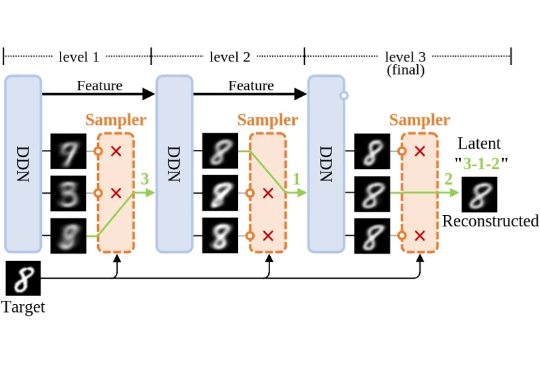
本项工作提出了一种全新的生成模型:离散分布网络(Discrete Distribution Networks),简称 DDN。相关论文已发表于 ICLR 2025。
在今年 ICLR 会议上,我们被问到最多且最有意思的问题是:像 Jina AI 这样的向量搜索模型提供商,除了在 MTEB 上做基准测试,会不会做些氛围测试 (Vibe-testing)?

上月,ChatGPT-4o无条件跪舔用户,被OpenAI紧急修复。然而,ICLR 2025的文章揭示LLM不止会「跪舔」,还有另外5种「套路」。

扩散模型(Diffusion Models)近年来在生成任务上取得了突破性的进展,不仅在图像生成、视频合成、语音合成等领域都实现了卓越表现,推动了文本到图像、视频生成的技术革新。然而,标准扩散模型的设计通常只适用于从随机噪声生成数据的任务,对于图像翻译或图像修复这类明确给定输入和输出之间映射关系的任务并不适合。
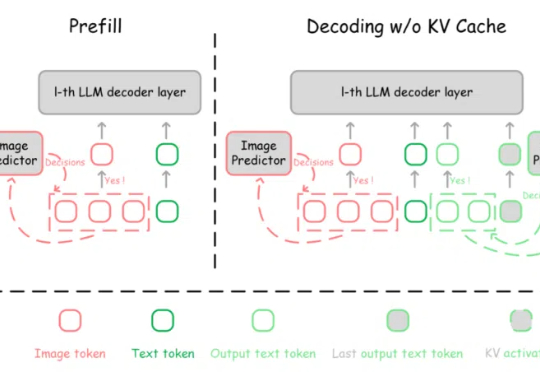
多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。